
RESTful API的设计
这是一篇写于两年多前的旧文了. 这里先贴下, 有空再更新
目录
概述
前后分离逐渐成为web开发的趋势。前后端通过api交换数据的架构迥异于以往的服务器端渲染。出于规范和扩展性考虑,根据RESTful API规范,整理出这份文档。
文档分为原则篇,架构篇,工具篇,实现篇四个部分。原则篇通过收集网络上关于RESTful API设计的文档,筛选部分认为实用性较高的原则整理而来。架构篇采用陈天的知乎专栏中关于架构方面的设计。工具篇主要介绍raml及相关工具的使用。实现篇则提供了一个基于tornado框架的demo。
原则篇
API优先
服务器
只使用https
总是使用TLS(就是https)来访问API,没有必要指出什么时候需要用,什么时候不需要用,只管任何时候都用它就好。
目前大部分web服务器同时使用http和https两种协议对外服务,只有小部分网站做到了全站https,并设置了http到https重定向。
API服务与普通web服务不同,不存在静态文件加速的考虑,因此实现全站https相对比较简单。另外,因为用户最初的请求通常是发送用户名密码获取token,若服务器允许http协议访问,则存在密码泄漏的风险。因此设置http到https的重定向是没有必要的。
请求
使用正确的请求方法
| 方法 | 描述 |
|---|---|
| OPTIONS | 用于获取资源支持的所有 HTTP 方法 |
| HEAD | 用于只获取请求某个资源返回的头信息 |
| GET | 用于从服务器获取某个资源的信息 |
| POST | 用于创建新资源 |
| PUT | 用于完整的替换资源或者创建指定身份的资源,比如创建 id 为 123 的某个资源 |
| PATCH | 用于局部更新资源 |
| DELETE | 用于删除某个资源 |
在请求body中接收JSON序列
不要将额外信息放到form-encoded里边,而是将其JSON序列放到PUT,PATCH或POST请求的Body中
GET, DELETE, HEAD请求的参数放在url里面,POST, PUT, PATCH, OPTION请求的参数必须以json格式放在请求体内部,类型允许application/x-www-form-urlencoded,multipart/form-data,application/json3种。
使用一致的路径格式
使用复数来命名资源,除非该资源在系统中是单件(比如,在绝大多数系统中,一个用户只能拥有一个账户)。这样在引用特定资源时可以保持一致性。
在RESTful API架构中,url代表某种资源,因此url中只能有名词,动词只能以参数形式传入。但是在某些文档的描述中,对独有资源的操作也可以通过在url中加动作来描述。
采用哪种可以根据后端框架风格来决定。通常不建议在url中包含动作,一般的动作直接用请求方法区别即可。
小写所有路径和属性
路径的命名使用小写字母和减号,属性的命名使用小写字母和下划线,例如
/server-api/app-setups
{
update_time: ""
expired_time: ""
}
响应
响应状态码
API的设计中,响应状态码的设计是最纠结的点之一。响应状态设计有两种风格,基于http状态码与error,msg风格。
RESTful API的规范是通过http status code标识,这样无需分析响应内容就能得知请求的状态。而且,在设计的时候统一遵守这一规范可以避免混乱的设计,方便用户使用。
很多REST API犯下的另一个错误是:返回数据时不遵循RFC定义的status code,而是一律200 ok + error message。这么做在client + API都是同一公司所为还凑合可用,但一旦把API暴露给第三方,不但贻笑大方,还会留下诸多互操作上的隐患。
但目前而言,大部分的API不遵循这一规范,有部分理由是http status code存在某些不足
对跨域请求,可能客户端无法识别除了200之外的其他状态码,以至于所有请求都是失败状态。
国内网络现状,非200请求可能会被劫持
相对而言,开发者对处理http status code较为陌生
另外,http status code可能会让人困惑,一个404的请求可能是链接错误(在类似tornado框架中就是路由无匹配,无法进行正常逻辑),也可能正常的查询逻辑之后返回空结果(亦即找不到该资源)。如果是请求静态资源,那么404状态只有一个原因,但是对相对复杂的应用逻辑而言,没有找到资源即返回404是不妥的。
结合上述情况,个人认为可以根据使用场景不同采纳不同的方案。
前后分离使用的api采用error,msg风格,这类api仅内部使用,可以不参照标准,通过内部沟通的方式,确定最高效的方式。
公共接口才用status code风格,这类api基本没有跨域访问的情况。参照标准的api才能称为RESTful api。
两套API后端逻辑通过函数封装可以实现某种程度的共用,但是不可能做到真正合二为一,因为两者的认证模式是不同的。web api使用的是cookie加session的方式认证,而公共接口通常使用auth token。
另外,也可以根据应用处理与否采用不同的方案。在后面架构篇中提到,在用户提交请求到请求被正常逻辑执行中间存在一系列预处理流程,比如频率限制,身份验证等。无法通过预处理的请求根据错误不过返回对应状态码,比如401要求身份验证,429请求过频等。通过预处理的请求一律以200返回,在返回内容中定义具体的状态码,类似微信API的全局返回码
完整的http status code请见文档->设计原则->http状态码参考
嵌入外键数据
将外键引用通过序列化的嵌入对象显示:
{
"name": "service-production",
"owner": {
"id": "5d8201b0..."
},
...
}
而不是这样:
{
"name": "service-production",
"owner_id": "5d8201b0...",
...
}
总是生成结构化的错误信息
为错误生成一致的,结构化的响应Body。包含机器可读的id,人类可读的message,以及可选的url指向关于错误的更多信息,还有如何解决它:
HTTP/1.1 429 Too Many Requests
{
"id": "rate_limit",
"message": "Account reached its API rate limit.",
"url": "https://docs.service.com/rate-limits"
}
为了同一套API可以给前端使用,建议多一个中文描述信息的字段。
其他备选
显示频率限制的状态
对客户端的频率限制可以保护服务的健康,并对其他的客户端提供高质量的服务。你可以使用token bucket 算法 来量化请求限制。
在每次请求的响应头中,通过RateLimit-Remaining 返回剩余的请求次数。
在所有的响应中压缩JSON数据
额外的空格增大了响应的大小,而很多人性化的客户端可以自动美化JSON输出。所以最好将JSON响应进行压缩:
{"beta":false,"email":"alice@heroku.com","id":"01234567-89ab-cdef-0123-456789abcdef","last_login":"2012-01-01T12:00:00Z", "created_at":"2012-01-01T12:00:00Z","updated_at":"2012-01-01T12:00:00Z"}
不要这样:
{
"beta": false,
"email": "alice@heroku.com",
"id": "01234567-89ab-cdef-0123-456789abcdef",
"last_login": "2012-01-01T12:00:00Z",
"created_at": "2012-01-01T12:00:00Z",
"updated_at": "2012-01-01T12:00:00Z"
}
可以考虑提供一个可选的方式来为客户端输出更长的响应,比如通过请求参数(如?pretty=true)或者通过 Accept头(如Accept: application/vnd.heroku+json; version=3; indent=4;)。
文档及其他
提供人类可读的文档
提供人类可读的文档帮助客户端开发者们理解你的API。
除了endpoint级别的描述,还要提供概要级别的信息,比如:
授权,包括获得和使用授权Token。
API的稳定性和版本,包括如何选择现有的API版本。
通用请求和响应头。
错误的序列化格式。
各种语言的客户端如何使用API的例子。
提供可执行的示例
提供可执行的例子,这样用户可以直接在终端输入并看到可以用的API请求。最好的情况是,这些例子可以直接复制粘贴,以最小化用户试用API的成本
描述稳定性
描述你API的稳定性,以及哪些endpoint依赖于其成熟度,比如使用prototype,development或者production的标识。
可参考 Heroku API compatibility policy 了解哪些接口是稳定的,哪些可能有变动。
一旦你的API宣布为 production-ready 和 稳定版,不要在该API版本上做任何不向前兼容的修改。如果你需要做不向前兼容的修改,创建一个新的版本号。
数据交换格式
超文本驱动和资源发现
这两篇文章(1,2)里均提到了RESTful API超文本驱动和资源发现的要求。
REST 服务的要求之一就是超文本驱动,客户端不再需要将某些接口的 URI 硬编码在代码中,唯一需要存储的只是 API 的 HOST 地址,能够非常有效的降低客户端与服务端之间的耦合,服务端对 URI 的任何改动都不会影响到客户端的稳定。
这样的描述可能会让人误解,更清楚的描述见怎么样才算是 RESTful?读 REST in Practice
客户端不再和 URI 紧耦合。在第 1 级或者第 2 级的应用里面,客户端都需要知道资源使用的 URI 模版(如 /orders/{id}),然后要操作什么样的资源就生成什么样的 URI。超媒体客户端只知道入口 URI,之后的每一个 URI 都是通过超链接获得的。
还是用上述论坛例子来解释,假若这个论坛通过 Atom 协议支持非浏览器的客户端访问。客户端是不需要知道论坛帖子的 URI 模版的,因为客户端可以通过帖子列表的 Atom 获得帖子的超链接,然后在用户选择浏览帖子时获取对应 URI 的内容。获取回来的结果不会带有 form,但会带有 ,通过这个 link 客户端又知道了用户提交的回复应该发往哪个 URI。
简而言之,在一个RESTful响应中,需要带有资源相关的方法以及相关资源的超链接,使得客户端可以通过响应来发现资源,无需强耦合先行指定url。
基于超文本驱动的api格式,根据HTTP 接口设计指北归纳,有下列4种。
- JSON HAL ,示例可以参考 JSON HAL 作者自己的介绍
- GitHub API 使用的方案 ,应该是一种 JSON HAL 的变体
- JSON API ,(这里有 @迷渡 发起的 中文版 ),另外一种类似 JSON HAL 的方案
- Micro API ,一种试图与 JSON-LD 兼容的方案
个人观点,在进行中小项目开发的时候,设计和维护一份规范的API文档既可以规避资源发现的要求,也降低了开发API的工作量(如何维护见工具篇)。就个人接触的项目现状,一个API链接通常只响应一个具体的操作,在没有成熟的框架的情况下,额外加入资源关联(资源发现)不仅会导致工作量增加,而且会给团队协作造成不便(如果同个模块多人维护更是雪上加霜)。
JSON API
JSON API 是数据交互规范,用以定义客户端如何获取与修改资源,以及服务器如何响应对应请求。
JSON API 是RESTful格式的一种,选择这一种的原因是有详细的中文文档。内容很多,无法一一列举,筛选也较为困难,最佳方法是在设计API的时候参考这份规范。
分页相关
架构篇
API结构设计主要借鉴再谈 API 的撰写 - 架构这篇文章。
一个API的处理流程可以概括为:发送请求->预处理->业务逻辑->后续处理->响应。对开发者而言,最理想的情况是只进行业务逻辑的开发,预处理以及后续处理交给框架来实现。
预处理
预处理逻辑可能包括:
访问频率控制
基本参数验证
自定义访问规则
用户身份验证
访问权限判断
请求数据验证
请求数据预处理
访问频率控制
不出意外,访问频率控制是接收请求的第一道门户(不计算系统防火墙等)。
在python实现中,访问频率控制有基于IP和基于用户身份两种。对外公开服务的API通常做法是基于IP的控制,能够有效屏蔽爬虫类程序的频繁请求。对内服务的API因为用户可能具有相同的IP而才用IP白名单,对白名单内的用户进行基于用户身份的控制。
RESTful API是无状态的,服务器无从得知用户的多次请求之间存在何种联系。在python实现中使用的是jwt(JSON Web Token)的方式验证,要求用户在请求头部包含用户的名称和token信息。因此基于身份的频率控制先对请求头进行判断,没有包含这两个基本信息的一律返回401错误。
存在内部恶意用户伪造身份使正常用户无法登录的情况,只能通过查看访问日志进行排查。
基本参数验证
在python实现中,基本参数包括用户名和Token两个。实际项目中,可能还包含请求的API版本号等。所有API请求都必须具有的参数在此验证
自定义访问规则
可定制的“防火墙”,建议将规则存放到数据库并提供交互界面以方便的进行规则的添加和修改。这里的规则通常以正则匹配为主,具有通用性,而单个API的控制尽量在API业务逻辑内部实现。
用户身份验证
在通过前面3道关卡的验证后,请求者当前是一位正常的陌生访客。如果API只提供给指定授权用户访问,那么在这一步进行用户的身份验证,否则可以略过。API的身份验证机制不能使用基于浏览器的cookie和session组合,而应该使用jwt或者auth2等
访问权限判断
这一步是Role Base ACL,根据授权用户分配的角色不同限制其访问范围。具体的权限控制列表应该在应用程序内设置好,因此该验证与应用耦合较高。
请求数据验证
在基本参数之外,每一个API都对请求的内容和参数有一定的要求。因为要求可能五花八门,通常的做法是在每一个API业务逻辑内部验证。但是可以通过强制规范来对这些要求进行收集然后集中在这一步进行处理。
在python实现中,使用raml规范API的设计并强制具体请求参数只能存在与url或者请求体中,通过提取解析raml规则,根据请求路由进行映射参数要求。
请求参数预处理
暂无实际实例
后续处理
从实用角度而言,后续处理主要包括两个:
响应数据格式化
访问统计
响应数据格式化
大部分API响应JSON格式的数据,适应多种场景的API设计应该考虑到允许用户指定响应格式,比如linux shell脚本开发者。通过约定返回数据格式(比如每个API响应均带有xml和text字段,或者数据主体存放在一个指定字段内),在这一步根据请求参数对响应进行过滤或者格式化
访问统计
基于IP的统计,用户身份的统计,单位时间的统计,报警逻辑等等
其他
篇首提到的文章有更详细的描述
工具篇
在约定了原则,确定了架构之后,依然有十分棘手的问题摆在开发者面前。
- 前后端分离的开发模式中,前后端对API具体格式和内容的约定
- 对外服务API的代码和文档的同步
使用工具就是为了解决这些痛点。
raml 概述
RESTful API火了许多年,但实际上没有一个统一的设计标准和流程。各类工具的优劣可以通过阅读大牛们的文章来了解(比如以上3篇)。简要概括:
markdown适合写文档但是不适合用于描述API这种具有多层嵌套的复杂结构
swagger功能强大且成熟,拥有完整的工具链
raml近年逐渐发展,有取代swagger之势
python实现里选择raml的主要原因是raml的工具相对而言更容易掌握,在工具链方面,已经拥有多语言解析器,web版编辑器,文档生成,api-console,编辑器插件,mock服务器,服务端代码生成等。下面介绍相关工具使用。
这些工具的组合技是这样的。
使用编辑器插件api-workbench的Editor tool辅助编写raml规范文档,该工具提供了自动补全和快捷按钮
使用osprey-mock-service搭建一个简易的api服务器(基于raml文档生成),供前端开发者使用
在编辑器内用api console简易测试,或者用谷歌浏览器插件postman测试
编写业务逻辑
使用raml2html生成并释出API文档
从这些步骤可以看出,编写API业务逻辑已经排在了靠后的步骤。
语法
以及raml目录下的文档。
raml与yaml语法基本一致,目前尚未全部吃透,仅指出一些例子
编辑器相关
web编辑器
swagger,blueprint,raml都提供了在线编辑器可以方便的编写规范文件并生成html文档,甚至提供内置测试脚本的文档。
RAML提供了名为API Designer的工具,可自行下载搭建一个web编辑器,也可以直接使用该公司托管在服务器的web编辑器。界面类似这样
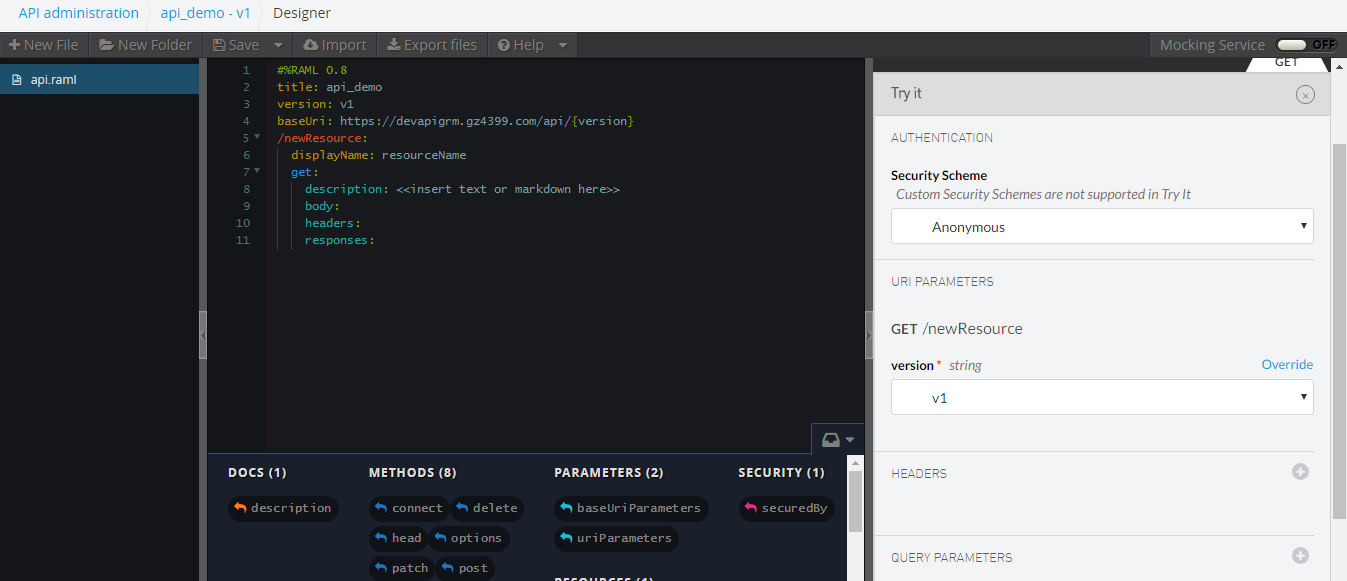
编辑器插件
RAML提供了名为api-workbench的基于Atom的编辑器插件,包含了生成模版,导入外部API,编辑工具,API测试页面等
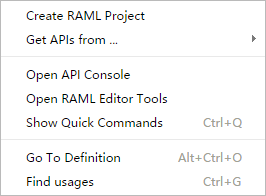
Editor Tools
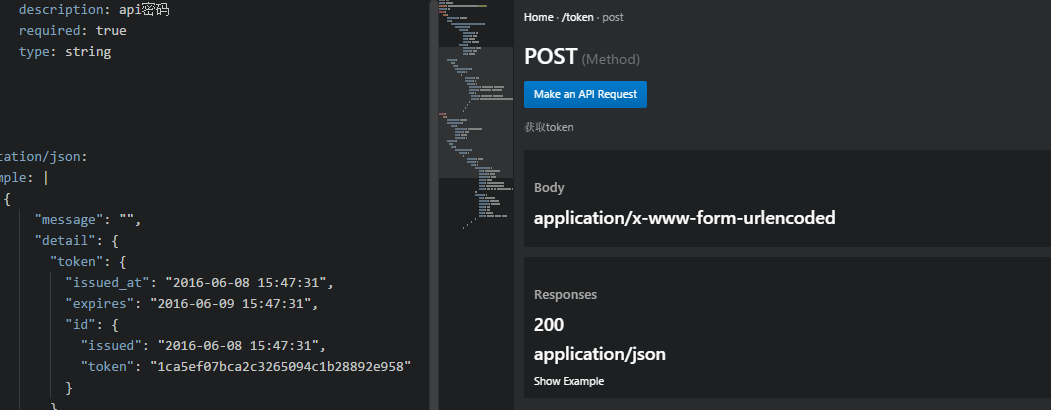
这是一个辅助编写RAML文件的工具,界面如图
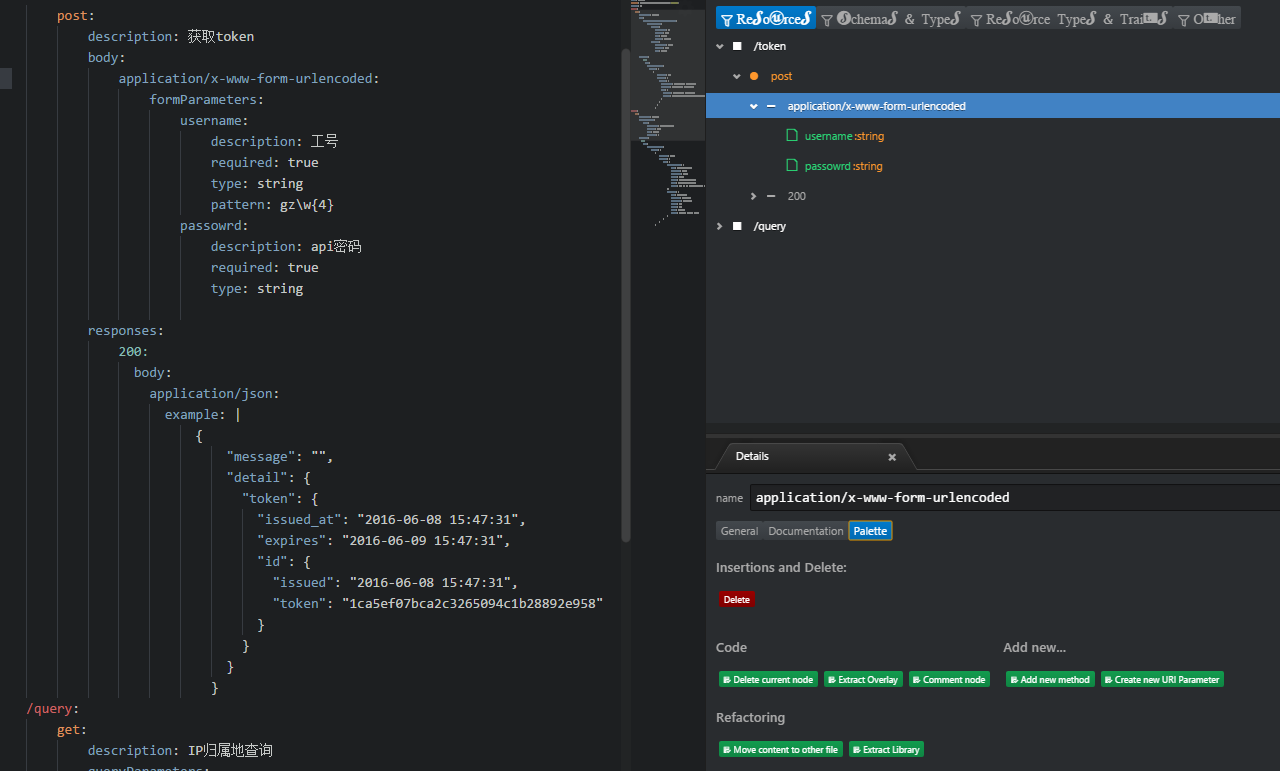
编辑器工作区右侧划分为两个窗口,上侧显示API的树形结构,下侧显示当前光标停留的节点的信息,切换到Palette标签会出现快捷按钮,点击按钮能够自动生成对应代码(节点,描述等)。
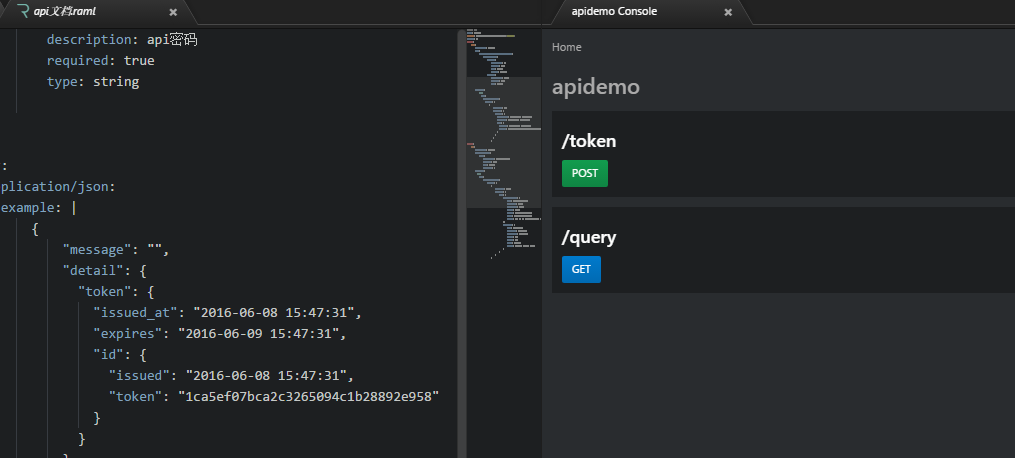
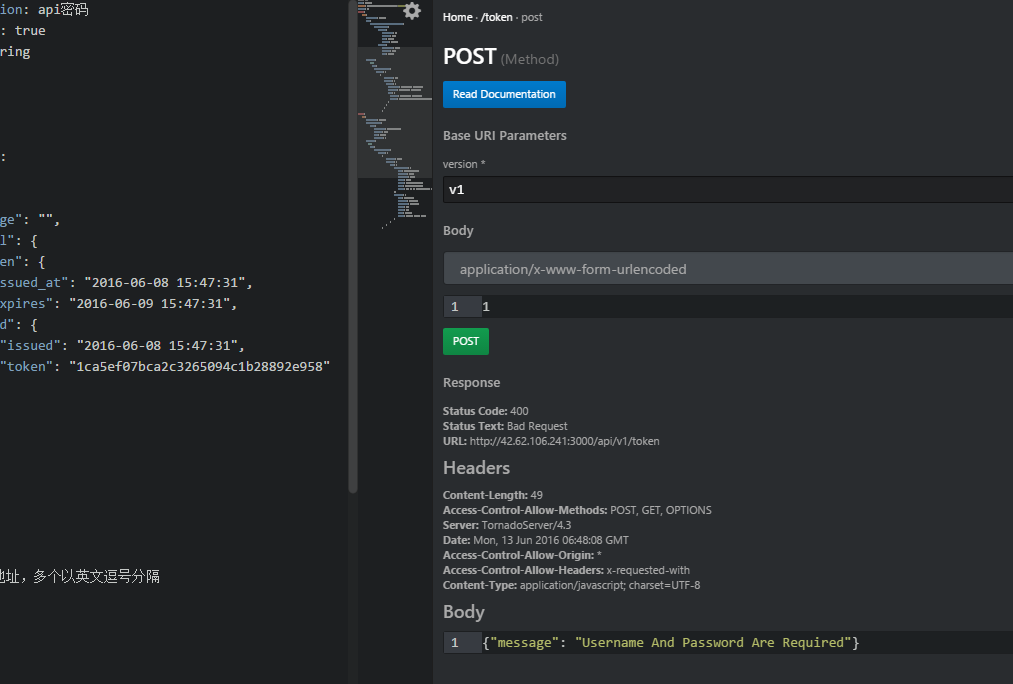
API Console
这是一个RAML将生成的文档预览以及测试工具,操作很简单,界面如图
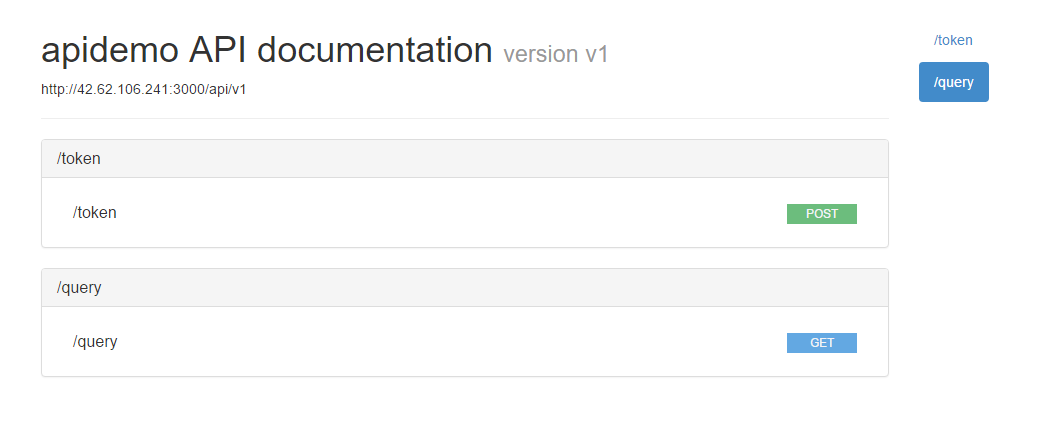
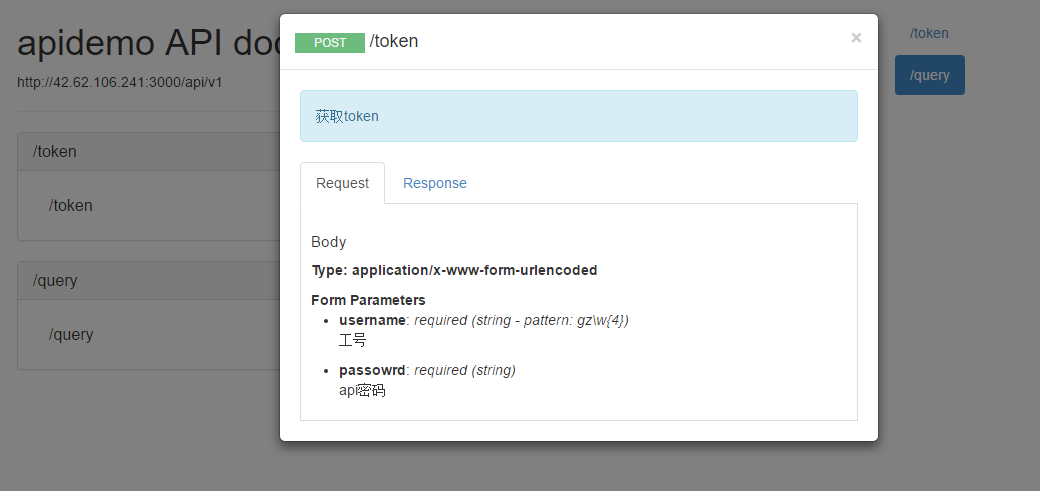
文档生成
文档生成用raml2html。
安装方法
npm i -g raml2html
使用方法
raml2html api.raml > api.html
生成的文档界面如图
在demo/docs目录下可以找到该文档
mock服务器
mock服务器可以启动一个简单的HTTP服务器,然后将一些静态的内容serve出来,以供前端代码使用。这样的好处很多: 1.前后端开发相对独立 2.后端的进度不会影响前端开发 3.启动速度更快 4.前后端都可以使用自己熟悉的技术栈(让前端的学maven,让后端的用gulp都会很不顺手)
mock服务器目前使用的是osprey-mock-service
安装方法
npm i -g osprey-mock-service
使用方法
osprey-mock-service -f api.raml -p 8000
服务器会监听本地8000端口接收API请求,返回每个API内example段设置的数据,请求不存在的url或者方法直接报错。
前后端开发者共同维护一份raml文档,前端开发者在本地根据raml启动mock服务器即可进行接口开发(这可能要求example要尽可能丰富)
RAML解析器
RAML目前有多个语言的解析器,python版本最出名的是ramlfications,将整个RAML解析为python一个对象。在python实现部分用于生成请求数据验证代码。
python实现
架构实现
在架构篇里阐述了预处理以及后续处理一些流程,在python里可以很方便的使用装饰器达到此效果。
在某个公共文件内声明一个装饰器函数AC,在具体API业务逻辑函数上使用。tornado框架根据路由匹配到某一业务逻辑函数时,装饰器先行进行频率控制,身份验证等步骤。在业务逻辑函数执行结束时,同样灵活地执行后续处理。
tornado中也可以通过重写RequestHandler.prepare(),RequestHandler.on_finish()函数来实现类似的效果。
跨域请求
详细的cors介绍请看这里:
要求tornado支持跨域请求,首先要在tornado.web.RequestHandler内重写options函数,使之能够响应外部请求
def options(self):
header = self.request.headers
self.set_header("Access-Control-Allow-Origin", "*")
self.set_header("Access-Control-Allow-Headers", header.get("Access-Control-Request-Headers"))
self.set_header("Access-Control-Allow-Methods", "GET,PUT,POST,DELETE")
self.set_header("Access-Control-Allow-Credentials", True)
self.set_header("Access-control-Max-Age", 100000)
self.finish()
另外,还需设定tornado默认响应头部信息,通过重写set_default_headers函数可以实现
def set_default_headers(self):
self.set_header("Access-Control-Allow-Origin", "*")
self.set_header("Access-Control-Allow-Headers", "x-requested-with")
self.set_header('Access-Control-Allow-Methods', 'POST, GET, OPTIONS')
频率限制
目前频率限制采用leaky bucket(token bucket)算法,关于此算法原理,参看请求速率限制问题。
使用redis作为数据存储,对超出限制的请求一律返回429错误。后续可引入报警机制。
请求参数验证
以往数据验证都是在业务逻辑函数内实现的,现在将其集中起来。
实现方法是,在服务器程序启动时,利用ramlfications解析器解析raml文件,提取出每一个API对参数的要求,生成一个囊括了所有API数据要求的字典。在装饰器内部,根据请求的uri和方法在字典中找到对应的限制条件进行判断。
